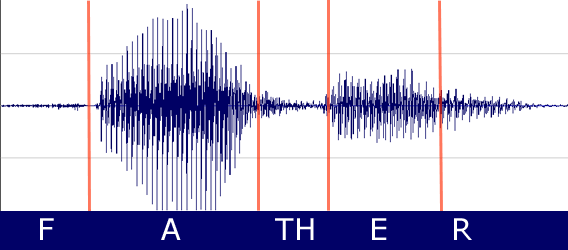
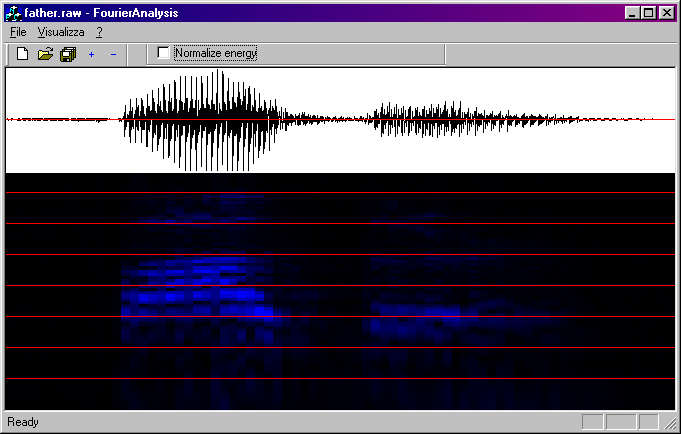
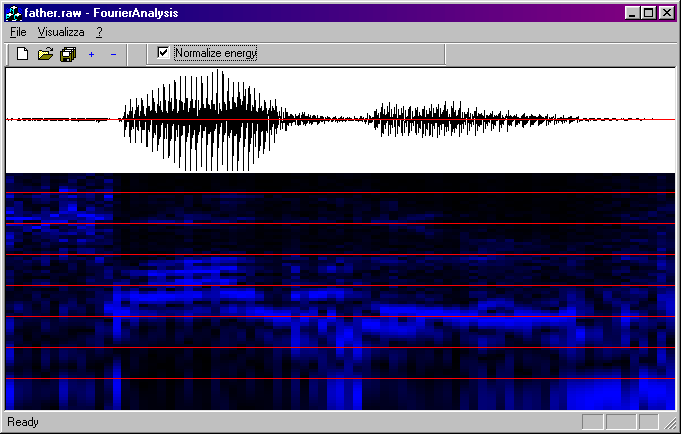
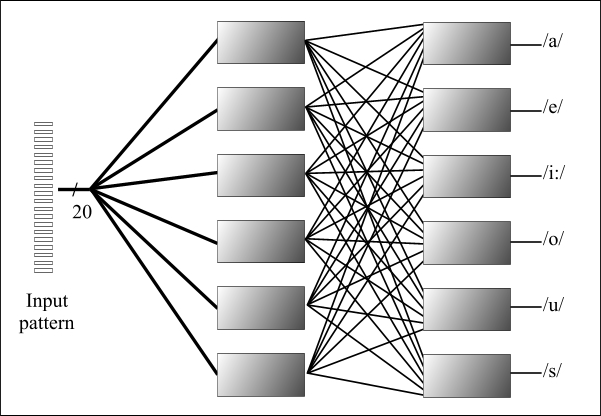
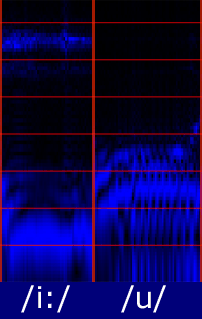
|
The results we will report were produced under the following conditions:
- loneliness killing threshold: 4 repetitions
- winning ratio threshold: 0.8
- training patterns as below:
| Phoneme | number of training patterns |
| /a/ | 236 |
| /e/ | 171 |
| /i/ | 104 |
| /o/ | 205 |
| /u/ | 169 |
| /s/ | 29 |
| /m/ | 78 |
| |
| total | 992 |
Training details: the log of the training is here reported.
The omitted parts contain no errors and no interesting data.
Testing frame 0: desired /a/, winner /a/, win ratio 0.000000
Testing frame 1: desired /a/, winner /a/, win ratio 0.000000
Testing frame 2: desired /a/, winner /a/, win ratio 0.000000
...
Testing frame 234: desired /a/, winner /a/, win ratio 0.000000
Testing frame 235: desired /a/, winner /a/, win ratio 0.000000
Testing frame 236: desired /e/, winner /e/, win ratio 0.103249
Testing frame 237: desired /e/, winner /e/, win ratio 0.101542
...
Testing frame 405: desired /e/, winner /e/, win ratio 0.050582
Testing frame 406: desired /e/, winner /e/, win ratio 0.079193
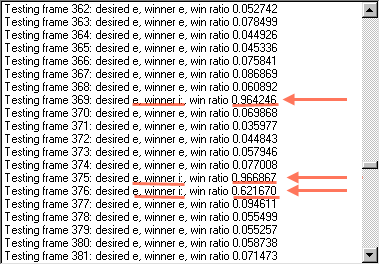
Testing frame 407: desired /i:/, winner /i:/, win ratio 0.275368
Testing frame 408: desired /i:/, winner /i:/, win ratio 0.279233
Testing frame 409: desired /i:/, winner /m/, win ratio 0.604378
Testing frame 410: desired /i:/, winner /i:/, win ratio 0.402855
Testing frame 411: desired /i:/, winner /i:/, win ratio 0.216688
...
Testing frame 509: desired /i:/, winner /i:/, win ratio 0.059101
Testing frame 510: desired /i:/, winner /i:/, win ratio 0.047175
Testing frame 511: desired /o/, winner /o/, win ratio 0.399943
Testing frame 512: desired /o/, winner /o/, win ratio 0.186259
...
Testing frame 713: desired /o/, winner /o/, win ratio 0.194598
Testing frame 714: desired /o/, winner /o/, win ratio 0.295468
Testing frame 715: desired /o/, winner /m/, win ratio 0.805574
Testing frame 716: desired /u/, winner /u/, win ratio 0.230878
Testing frame 717: desired /u/, winner /u/, win ratio 0.188211
...
Testing frame 883: desired /u/, winner /u/, win ratio 0.121368
Testing frame 884: desired /u/, winner /u/, win ratio 0.429669
Testing frame 885: desired /s/, winner /m/, win ratio 0.826323
Testing frame 886: desired /s/, winner /s/, win ratio 0.695413
Testing frame 887: desired /s/, winner /i:/, win ratio 0.203407
Testing frame 888: desired /s/, winner /s/, win ratio 0.218484
Testing frame 889: desired /s/, winner /s/, win ratio 0.206388
...
Testing frame 912: desired /s/, winner /s/, win ratio 0.590790
Testing frame 913: desired /s/, winner /s/, win ratio 0.489405
Testing frame 914: desired /m/, winner /o/, win ratio 0.979688
Testing frame 915: desired /m/, winner /o/, win ratio 0.527820
Testing frame 916: desired /m/, winner /m/, win ratio 0.787123
Testing frame 917: desired /m/, winner /m/, win ratio 0.860028
...
Testing frame 990: desired /m/, winner /m/, win ratio 0.218466
Testing frame 991: desired /m/, winner /m/, win ratio 0.160790
Errors = 4, error percentage = 0.403 %
Correctly discarded= 4, incorrectly discarded = 2
Recognized string postprocessing: /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/
...
/a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/
/a/ /a/ /a/ /a/ /a/ /a/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/
/e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/
/e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/
...
/e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/
/e/ /e/ /e/ /e/ /e/ /e/ /e/ /i:/ /i:/ /m/ /i:/ /i:/ /i:/ /i:/ /i:/
/i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/
...
/i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/
/i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /o/ /o/ /o/
/o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/
...
/o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/
/o/ /o/ /o/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/
/u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/
...
/u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/
/u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /s/ /i:/ /s/ /s/ /s/ /s/ /s/ /s/
/s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/
/s/ /s/ /o/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /u/ /m/ /m/ /m/ /m/ /m/ /m/ /m/
/m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/
...
/m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/
/m/ /m/ /m/ /m/
After encoding change: (/a/, 236) (/e/, 171) (/i:/, 2) (/m/, 1) (/i:/, 101)
(/o/, 204) (/u/, 169) (/s/, 1) (/i:/, 1) (/s/, 26) (/o/, 1) (/m/, 7) (/u/, 1) (/m/, 65)
Average repetition value = 70.428571
Repetition value variance = 5.030612
After removing and soldering:
(/a/, 236) (/e/, 171) (/i:/, 101) (/o/, 204) (/u/, 169) (/s/, 26) (/m/, 72)
After killing lonely phonemes: /a/ /e/ /i:/ /o/ /u/ /s/ /m/
Results:
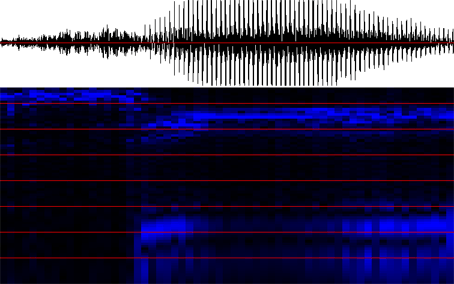 |
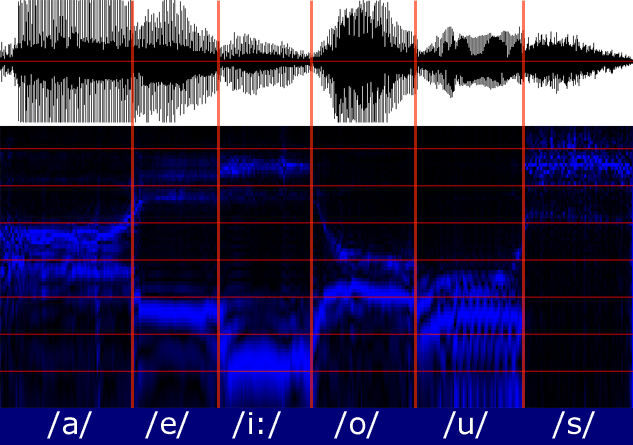
"see" (English) [si:]
Recognized string postprocessing: /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /i:/ /e/ /u/ /i:/ /s/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /m/ /i:/ /i:/ /i:/ /i:/ /m/
After encoding change: (/s/, 18) (/i:/, 1) (/e/, 1) (/u/, 1) (/i:/, 1) (/s/, 1) (/i:/, 24) (/m/, 1) (/i:/, 4) (/m/, 1)
Average repetition value = 5.300000
Repetition value variance = 0.530000
After removing and soldering: (/s/, 18) (/i:/, 28)
After killing lonely phonemes: /s/ /i:/
|
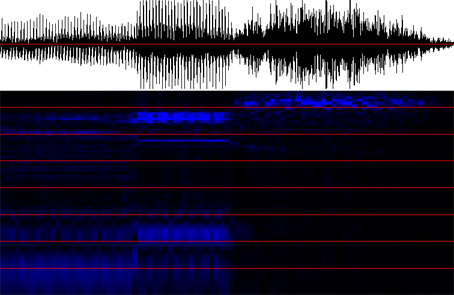 |
"miss" (English) [mi:s]
Recognized string postprocessing: /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /i:/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/
After encoding change: (/m/, 27) (/i:/, 19) (/s/, 43)
Average repetition value = 29.666667
Repetition value variance = 9.888889
After removing and soldering: (/m/, 27) (/i:/, 19) (/s/, 43)
After killing lonely phonemes: /m/ /i:/ /s/
|
 |
"maus" (German) [maus]
Recognized string postprocessing: /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /o/ /o/ /o/ /u/ /e/ /m/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /u/ /m/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /o/
After encoding change: (/m/, 23) (/a/, 34) (/o/, 3) (/u/, 1) (/e/, 1) (/m/, 1) (/u/, 9) (/m/, 1) (/s/, 37) (/o/, 1)
Average repetition value = 11.100000
Repetition value variance = 1.110000
After removing and soldering: (/m/, 23) (/a/, 34) (/u/, 9) (/s/, 37)
After killing lonely phonemes: /m/ /a/ /u/ /s/
|
 |
"mé so měa" (Dialect Cremasco) [me so 'mi:a]
Recognized string postprocessing: /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /e/ /m/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /s/ /m/ /e/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /o/ /a/ /o/ /m/ /m/ /m/ /m/ /u/ /m/ /m/ /m/ /u/ /u/ /i:/ /u/ /i:/ /i:/ /i:/ /i:/ /i:/ /e/ /m/ /m/ /e/ /m/ /m/ /m/ /e/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /m/ /u/ /u/ /u/ /s/ /e/ /e/ /e/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/ /a/
After encoding change: (/m/, 30) (/e/, 59) (/m/, 1) (/s/, 34) (/m/, 1) (/e/, 1) (/o/, 18) (/a/, 1) (/o/, 1) (/m/, 4) (/u/, 1) (/m/, 3) (/u/, 2) (/i:/, 1) (/u/, 1) (/i:/, 5) (/e/, 1) (/m/, 2) (/e/, 1) (/m/, 3) (/e/, 1) (/m/, 9) (/u/, 3) (/s/, 1) (/e/, 3) (/a/, 9)
Average repetition value = 7.538462
Repetition value variance = 0.289941
After removing and soldering: (/m/, 30) (/e/, 59) (/s/, 34) (/o/, 18) (/m/, 4) (/i:/, 5) (/m/, 9) (/a/, 9)
After killing lonely phonemes: /m/ /e/ /s/ /o/ /m/ /i:/ /m/ /a/
|
|